MongoTemplate的优化引发FullGC导致服务假死
标签: #技术/JVM #效能工具/内存分析工具 #Share
问题表现
- 内部收到JVM告警,其表现为:
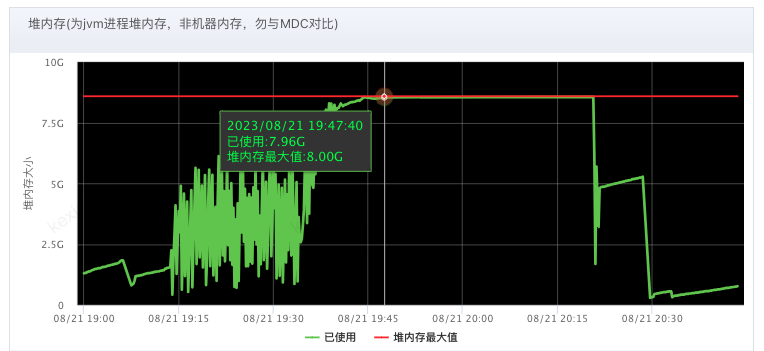
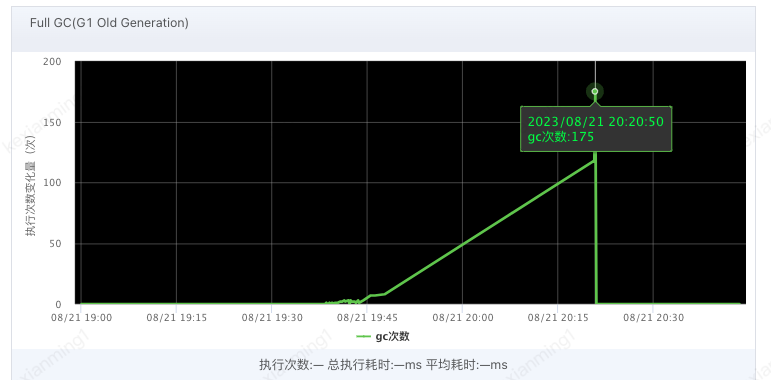
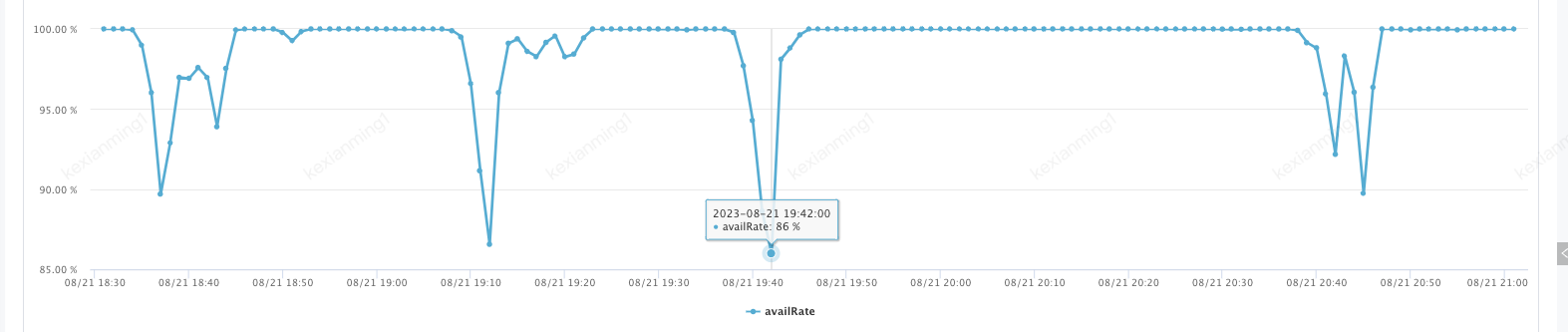
- 外部应用反馈接口可用率/耗时严重波动
止损方案
- 观察核心接口的响应时间,在发现低响应机器时立即下线JSF流量
- 观察UMP的内存使用情况,发现较为异常GC机器,提前下线JSF流量
- 观察MDC情况,发现CPU异常情况,提前下线JSF流量
影响
由于发现及时,响应及时,再加上是B端流程,各个下游都有相关的兼容策略,所以仅是告警较多,没有产生大的业务影响。
排查思路
当晚我们组织了几个人从多个角度分别去排查:
JVM堆栈进行分析
基于该条线路定位到了内存中的大对象,相关方法
业务流量、多维监控、机器日志、异常请求
基于该条线路定位到了某一次Trace请求一共花了50分钟才结束,也间接知道了相关方法
脑暴思考发生这种周期性问题的场景,例如周期性请求、MQ重试等,观察相关的数据
快速定位的手段 Dump日志分析
实际上我们在定位该问题时花费的时间较长,原因是Dump日志过大以及相关分析能力不够熟练,但同一个错误不犯第二次,未来再出现类似情况有信心在10分钟之内定位。
定位相关问题必做的两件事:
- 保留问题现场
- 问题机器务必摘掉流量
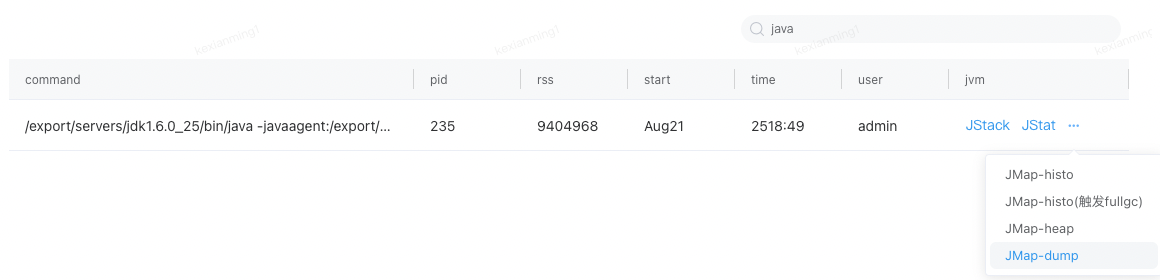
由于该问题是典型的OOM导致疯狂FullGC,那一定存在大对象,利用行云/机器的Jmap命令可以获取其Dump日志,我们采用的是行云工具:
困境:Dump日志过大
这是我们在定位问题时遇到的第一个问题,Dump日志过大,压缩包为1.8G左右,解压后文件大小为10.8G左右,下载传输本来就很耗时,同事们的MAT工具第一次尝试打开的时候还总失败,给MAT工具加大内存后,打开一个超大Dump日志还比较随缘,要么电脑死机,要么需要10分钟左右。
后续又研究了一下,同一文件打开的速度如下:
MemoryAnalyzerTool:10分钟左右且需要主动调节最大内存,不太稳定。
Visual VM:20分钟左右且需要主动调节最大内存,打开后如果涉及分析引用,又需要几十分钟。
为了未来定位更加高效,从市面上筛选了一下更新的分析工具,最终确定到这一款:YourKit Java Profiler。
下载地址为:https://www.yourkit.com/java/profiler/download/
这款软件导入11G左右的Dump日志(Mac 16G内存电脑 M1芯片)只需要40秒左右,后续涉及计算的部分大概也都是5秒钟之内能够响应。
YourKitJavaProfiler
基于上述问题整个分析与操作的过程如下:
将拿到的文件解压后修改后缀名为:.hprof
导入YourKitJavaProfiler中(File - Open snapshop…)
需要大概几十秒到1分钟的时间,进度条非常给力,不会让人害怕突然崩掉
选择类视图,排序后找到堆当中明细异常的对象(很好发现)
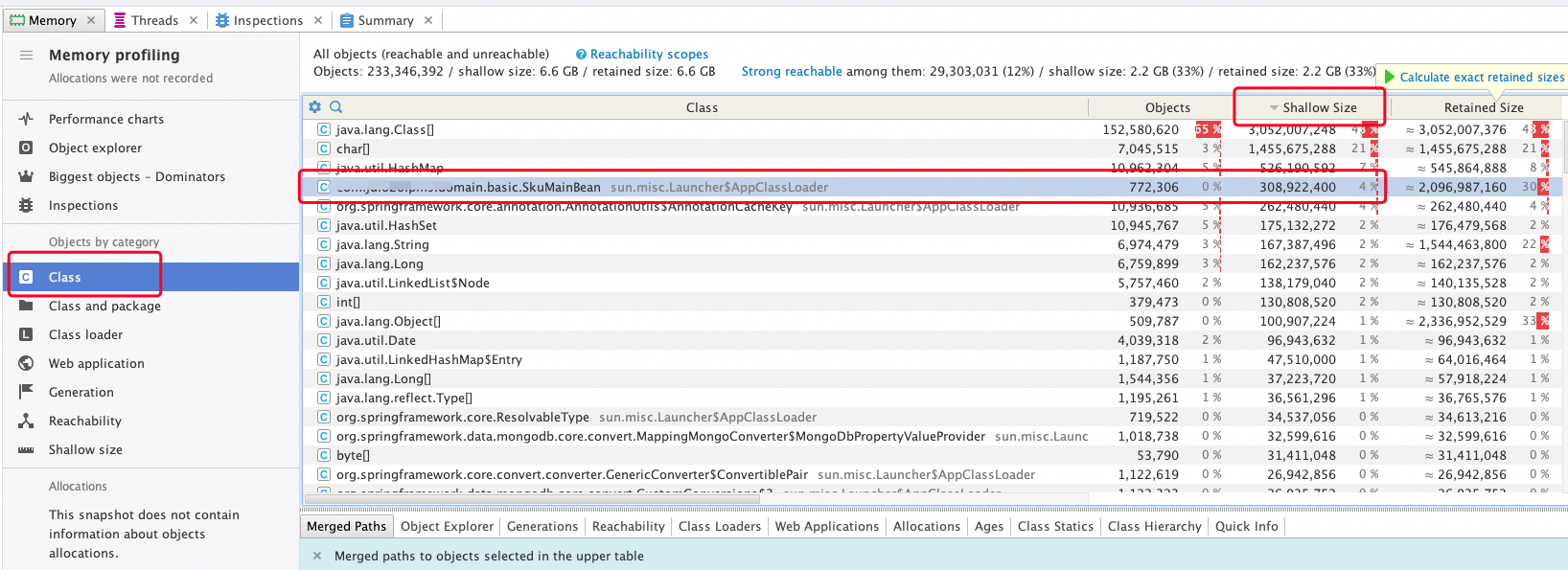
- 右键,进入该对象的深入分析
可以看到这个对象的占用非常高,查看其GC Roots 可以看到似乎是一个ArrayList里放了77万个该对象,另外相关的线程名是:JSF-BZ-22000-203-T-15
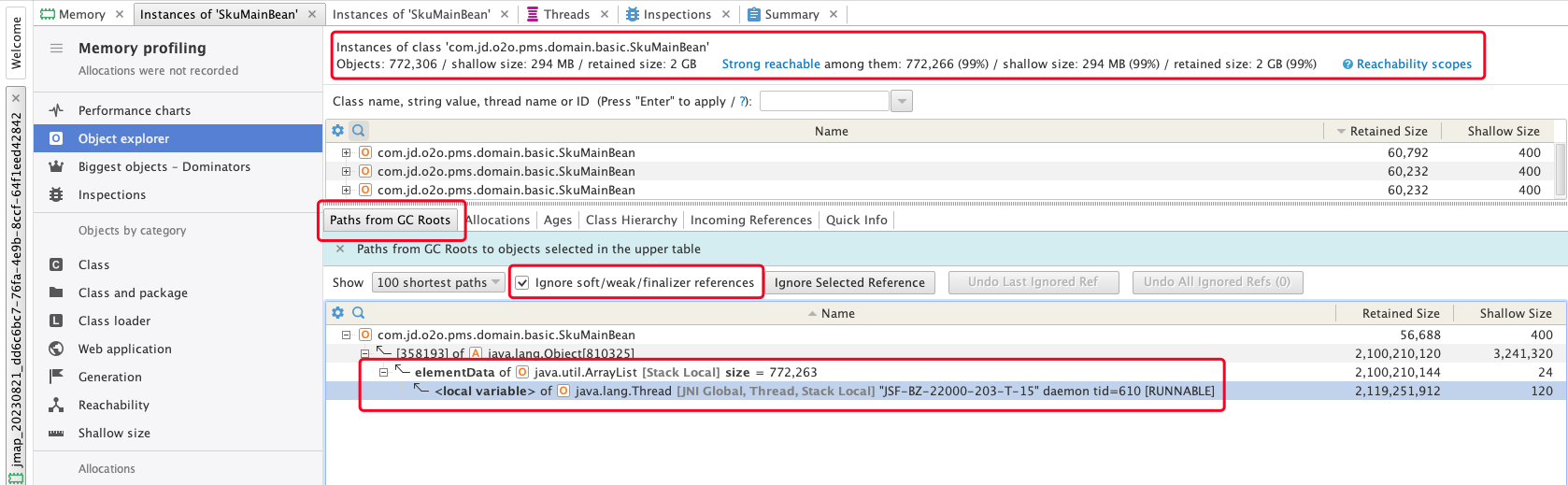
- 从Incoming References中也可以得到相同的结果
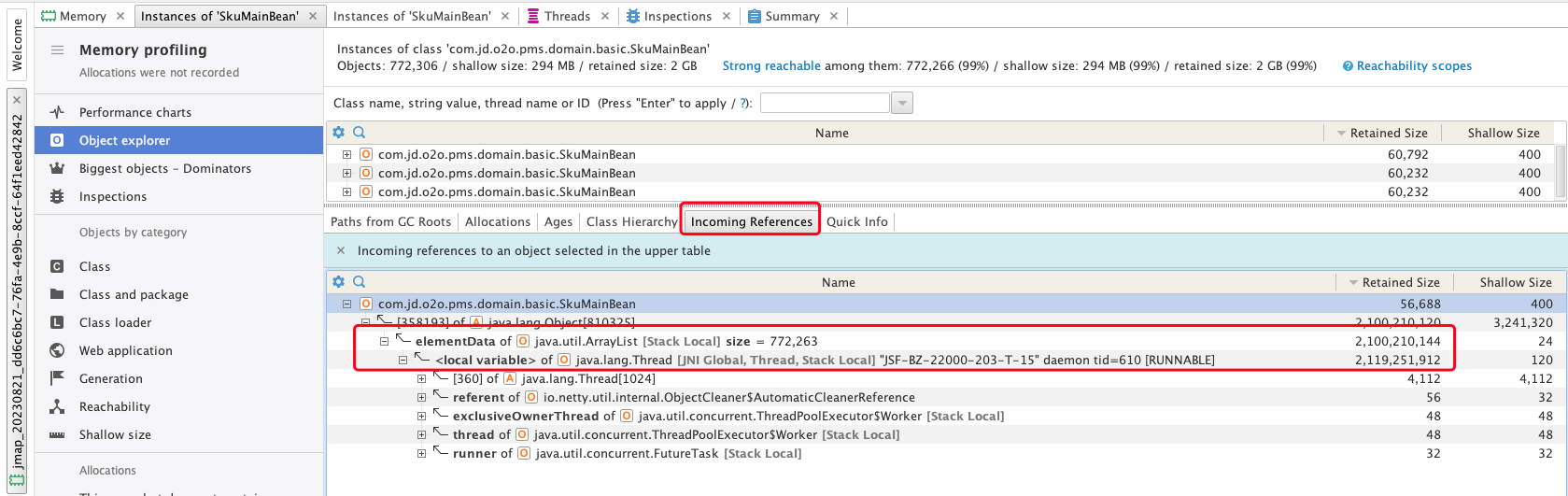
- 知道线程名后,进入线程界面进行查询
该模型可以支持按线程名或ID查询,然后就是熟悉的调用链路了,按照从下往上看的原则,慢慢找的话,一定可以找到和我们相关的异常之处。
可以点击 Thread ID:610,进入更细节的链路之中。
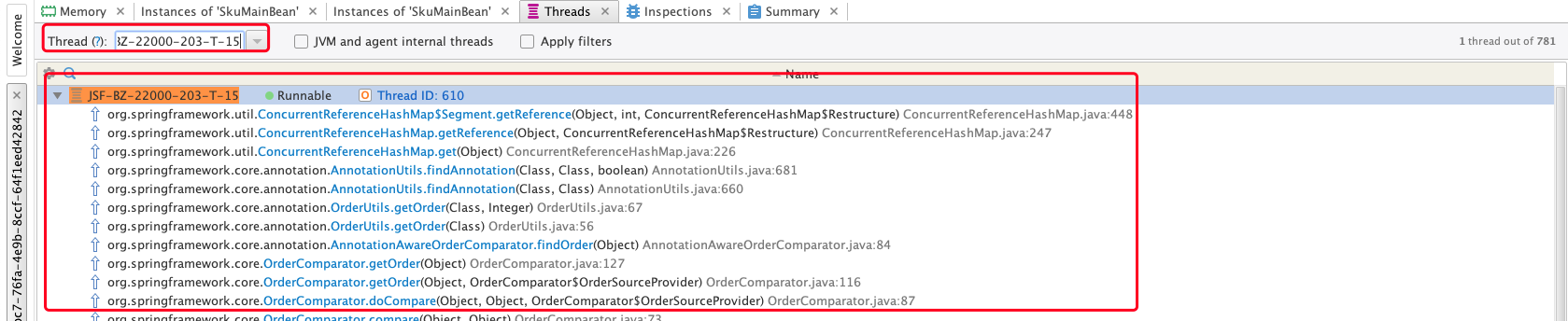
- 拿到请求入参
我们发现整个调用链路中有一个核心对象承接了请求入参,代码如下:
// SkuMainInfoRequest类即是请求体
ServiceResponse<SkuMainParterResponse> updateSkuBaseInfo(SkuMainInfoRequest request)我们拿这个对象去搜索,可以得到更细节的内容
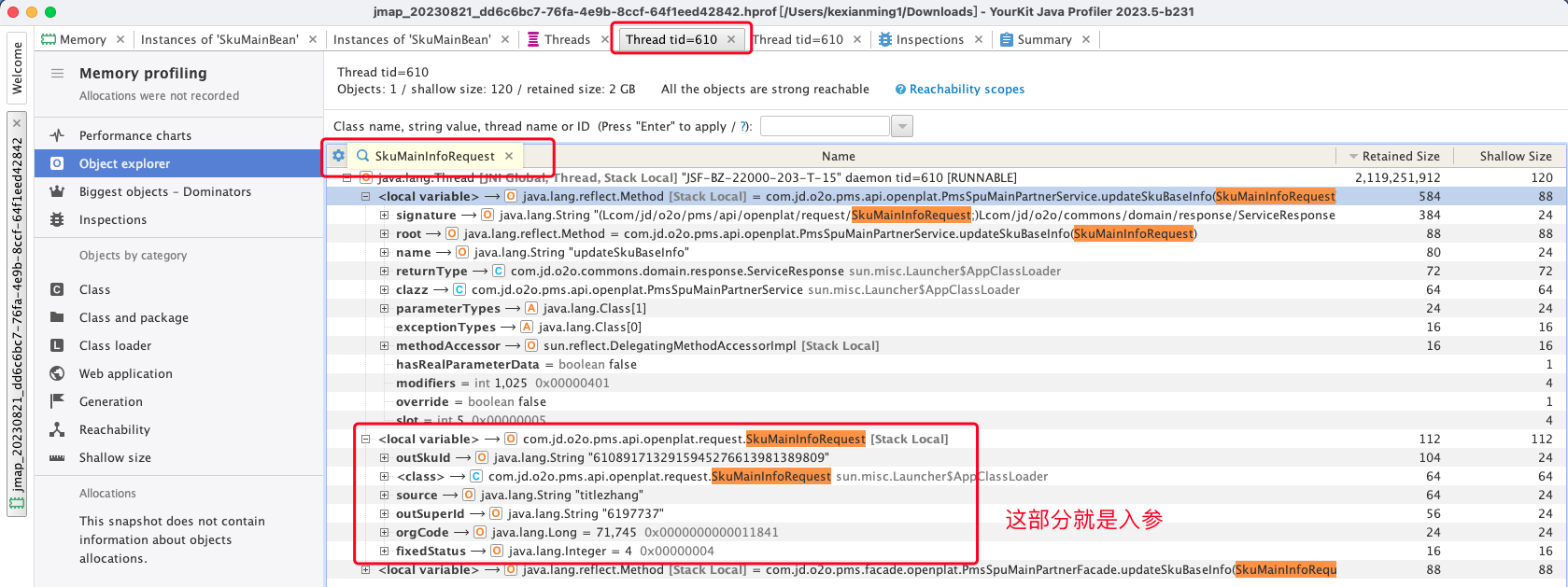
- 拿到入参和入口后,用安全的机器多调用几次,查看表现是否符合预期,然后继续定位Bug,修复上线即可。
问题根因
由于上文的分析流程,我们很容易就知道了到底什么参数什么情形引起了该问题,继续分析发现其实很简单,即:
某一次 IN 查询时IN的是一个包含Null值的集合(不符合预期,相关数据起码几十万条),如下:
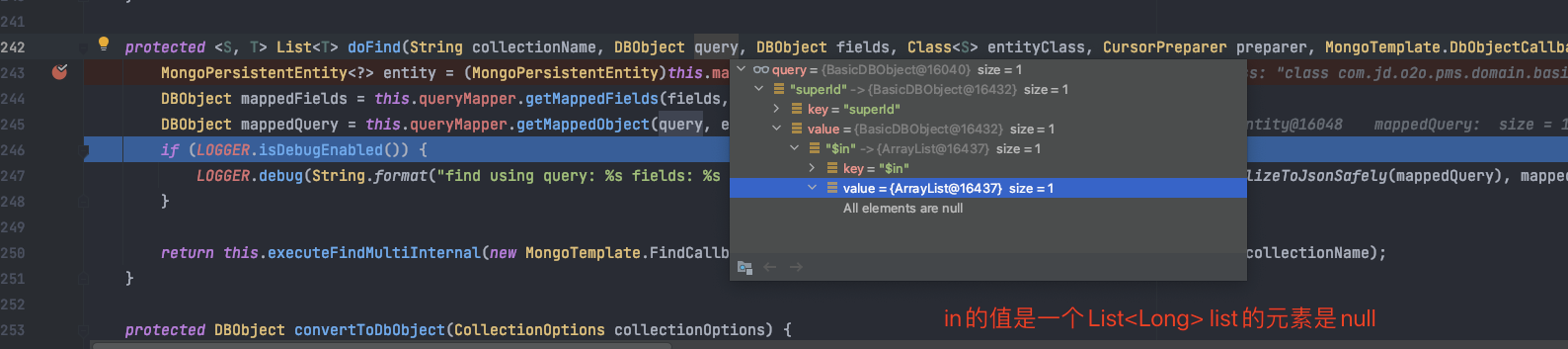
其实按照我们朴素的直觉来看,这样的问题应该是一个慢查询,带来的影响应该是慢查询导致线程耗尽,服务器受影响,不应该是疯狂FullGC的。
在跟进MongoTemplate的客户端代码后发现,它底层在进行 find 查询时使用的是游标的方式。
核心方法:org.springframework.data.mongodb.core.MongoTemplate#executeFindMultiInternal
截图:
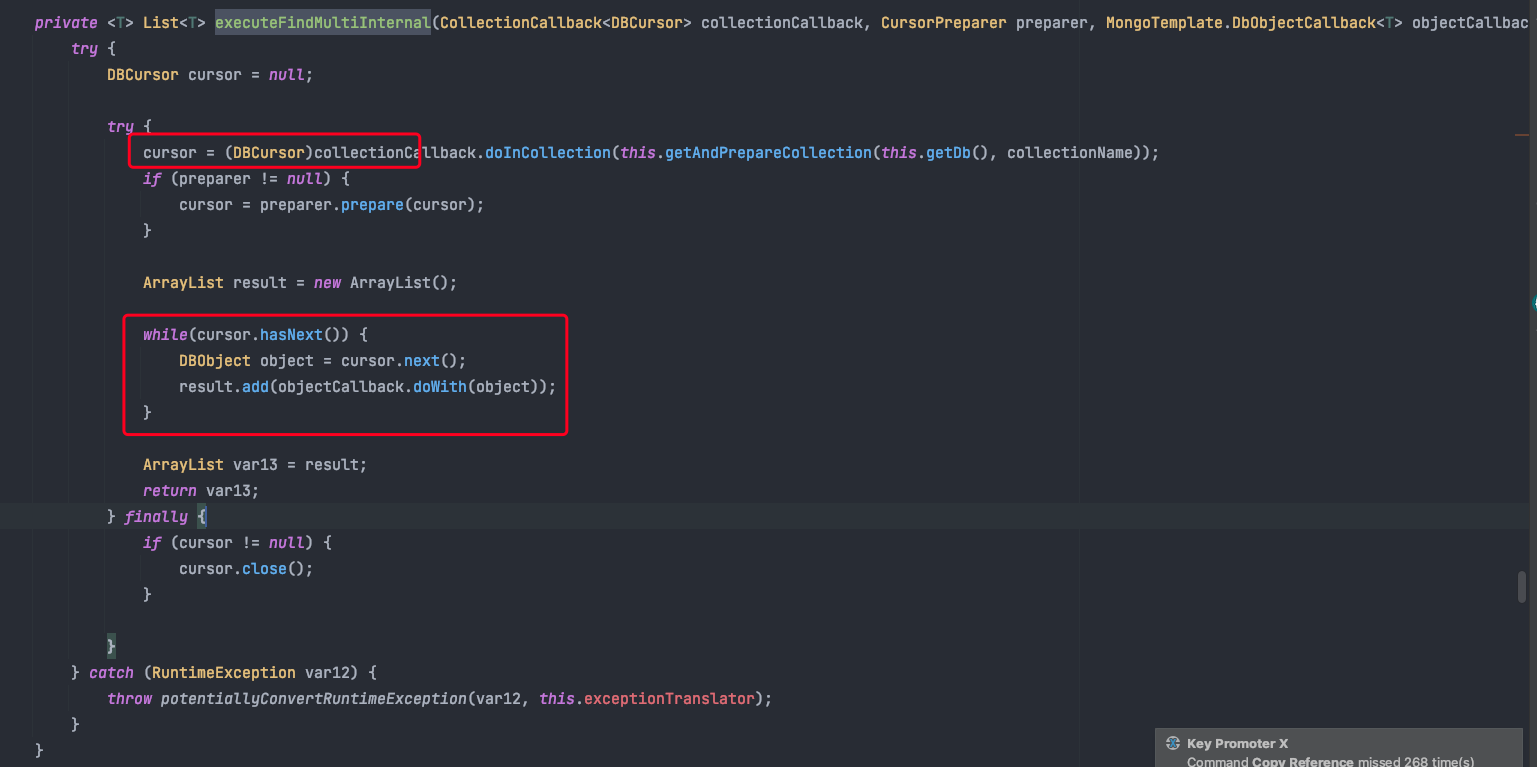
怎么说呢,感谢MongoTemplate做出的优化,不然我们遇到的问题可能是数据库宕机,那就非常糟糕了。
所以结论就是:
业务代码中某一次判断不太合适,让程序执行了一次 IN NULL 的操作(涉及几十万条数据),由于MongoTemplate的底层优化,让我们避免了数据库宕机的风险,但是导致拿的数据太多存储在内存之中,一直触发FullGC,进而服务器假死。
最后
花了一定时间研究内存分析工具之后,深感其能力的强大,也让我有信心在下次遇到类似问题时,5-10分钟即可定位。
另外,在发现工具用的相当不顺手时,也要果断的寻找新的解决之道。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!