布隆过滤器
标签: #Share
什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的
布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
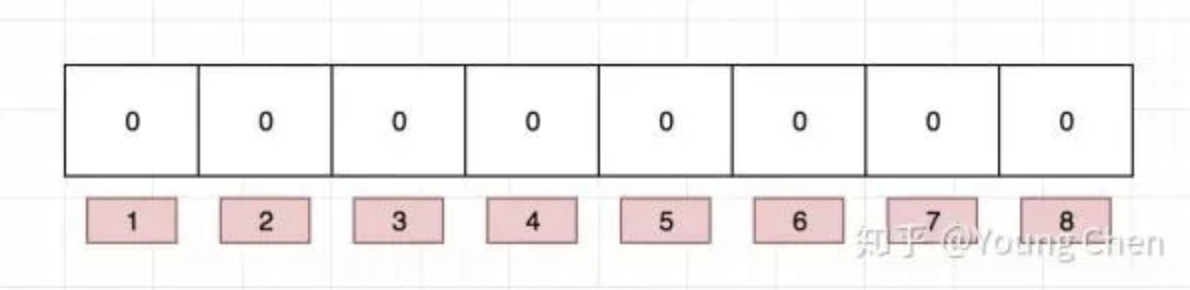
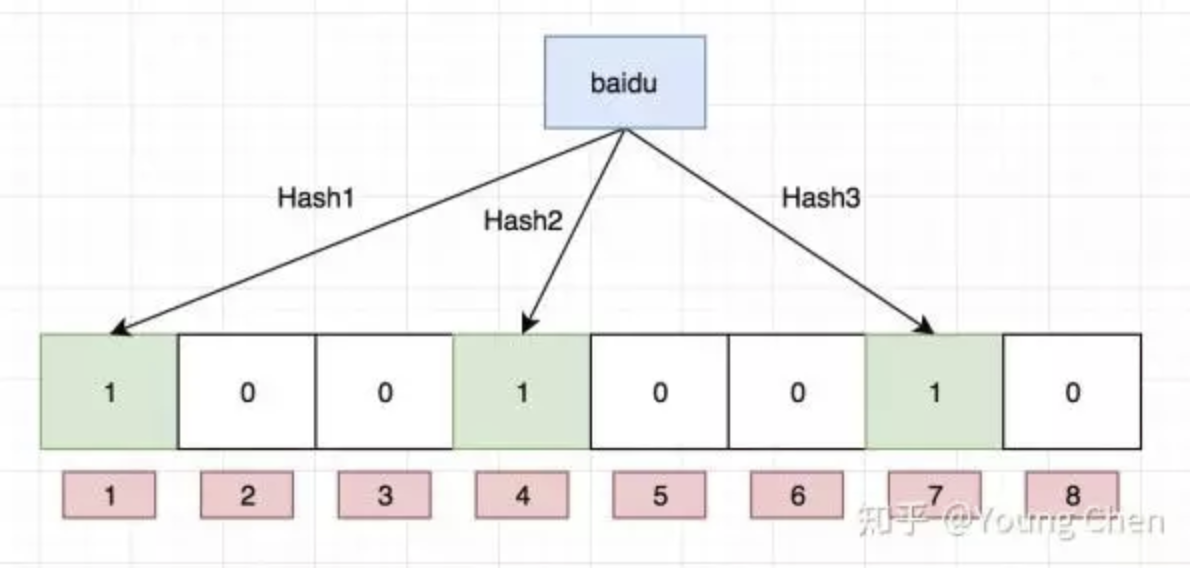
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
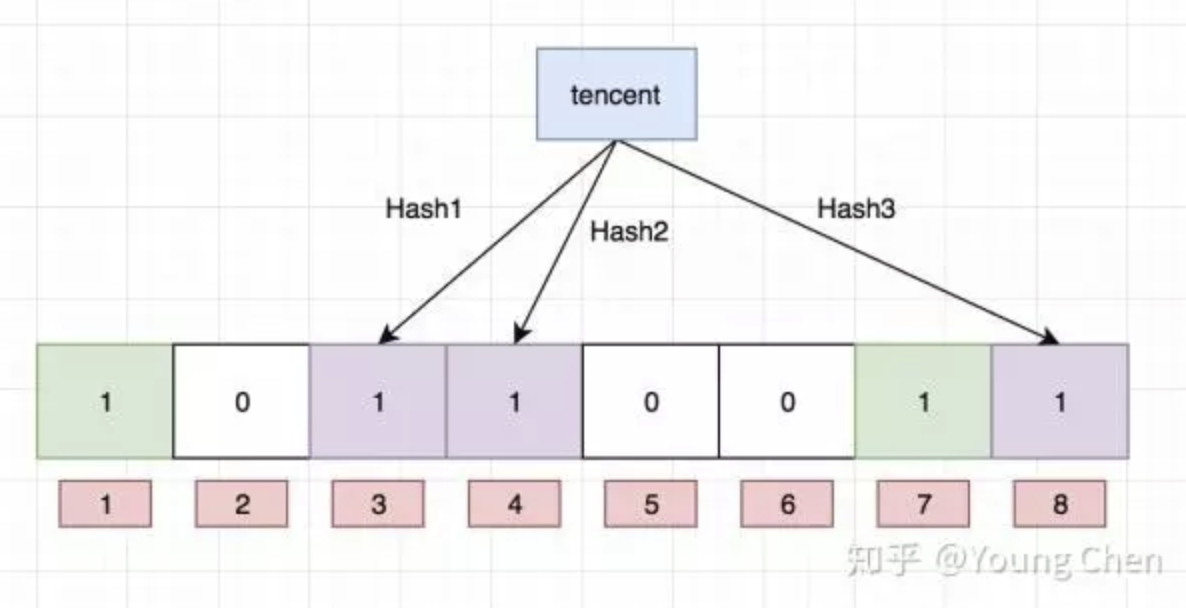
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在
支持删除么
目前我们知道布隆过滤器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上图中的 bit 位 4 被两个值共同覆盖的话,一旦你删除其中一个值例如 “tencent” 而将其置位 0,那么下次判断另一个值例如 “baidu” 是否存在的话,会直接返回 false,而实际上你并没有删除它。
如何解决这个问题,答案是计数删除。但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。这样的话,增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0
快速集成BloomFilter
关于布隆过滤器,我们不需要自己实现,谷歌已经帮我们实现好了。
- pom引入依赖
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>- 核心api
/**
* Creates a {@link BloomFilter BloomFilter<T>} with the expected number of
* insertions and expected false positive probability.
*
* <p>Note that overflowing a {@code BloomFilter} with significantly more elements
* than specified, will result in its saturation, and a sharp deterioration of its
* false positive probability.
*
* <p>The constructed {@code BloomFilter<T>} will be serializable if the provided
* {@code Funnel<T>} is.
*
* <p>It is recommended that the funnel be implemented as a Java enum. This has the
* benefit of ensuring proper serialization and deserialization, which is important
* since {@link #equals} also relies on object identity of funnels.
*
* @param funnel the funnel of T's that the constructed {@code BloomFilter<T>} will use
* @param expectedInsertions the number of expected insertions to the constructed
* {@code BloomFilter<T>}; must be positive
* @param fpp the desired false positive probability (must be positive and less than 1.0)
* @return a {@code BloomFilter}
*/
public static <T> BloomFilter<T> create(
Funnel<T> funnel, int expectedInsertions /* n */, double fpp) {
checkNotNull(funnel);
checkArgument(expectedInsertions >= 0, "Expected insertions (%s) must be >= 0",
expectedInsertions);
checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);
checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
/*
* TODO(user): Put a warning in the javadoc about tiny fpp values,
* since the resulting size is proportional to -log(p), but there is not
* much of a point after all, e.g. optimalM(1000, 0.0000000000000001) = 76680
* which is less than 10kb. Who cares!
*/
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel,
BloomFilterStrategies.MURMUR128_MITZ_32);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
/**
* Returns {@code true} if the element <i>might</i> have been put in this Bloom filter,
* {@code false} if this is <i>definitely</i> not the case.
*/
public boolean mightContain(T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}- 一个小例子
public static void main(String... args){
/**
* 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器
*/
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);
bloomFilter.put("121");
bloomFilter.put("122");
bloomFilter.put("123");
System.out.println(bloomFilter.mightContain("121"));
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!